
Portkey AI
Last updated:
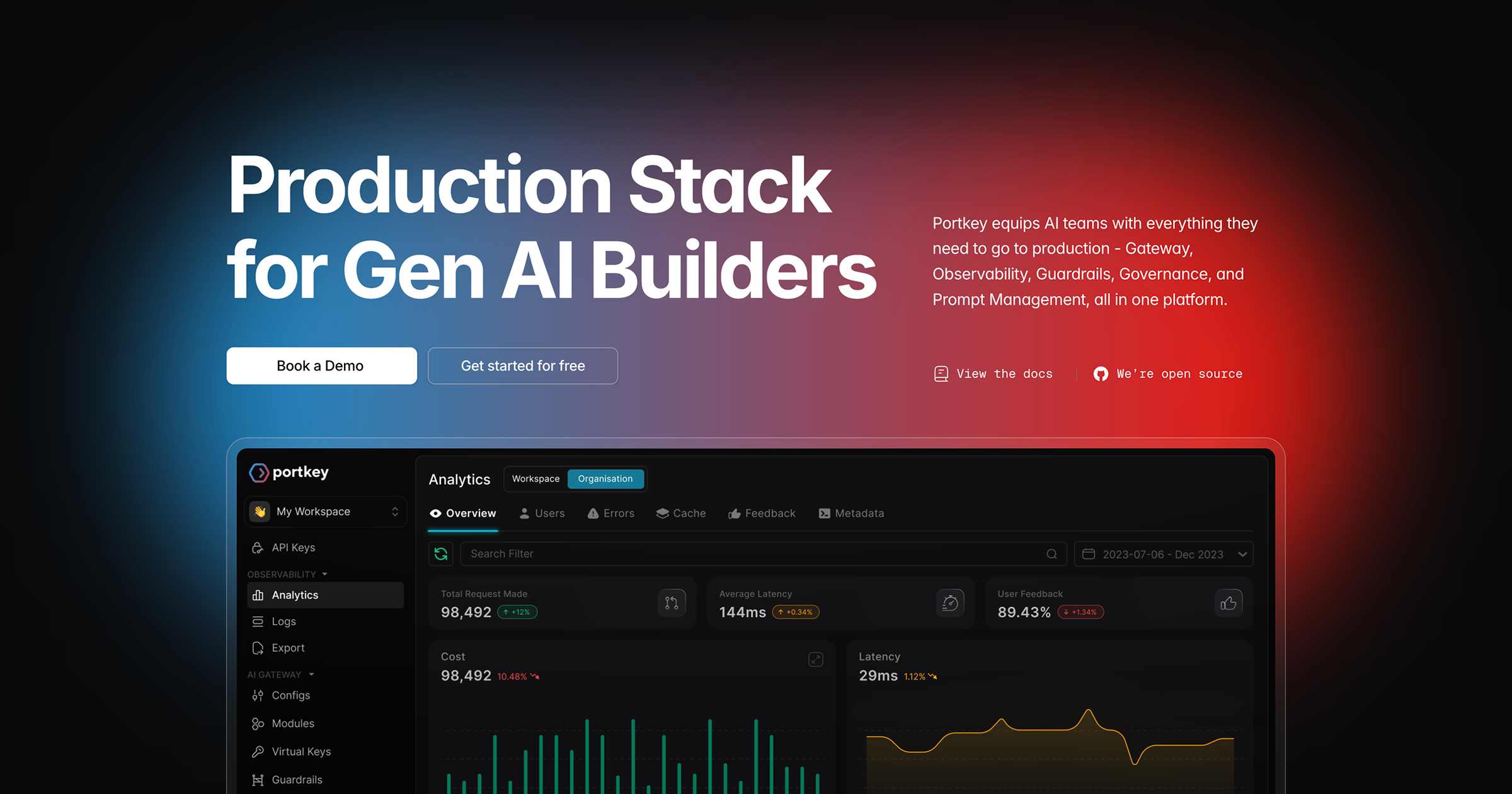
Portkey AI is an advanced AI control panel designed for developers and AI teams to monitor, govern, and optimize their LLM (Large Language Model) interactions and AI applications. It offers a robust AI Gateway for unified API access, performance enhancements, and reliability features, alongside an Observability Suite for real-time monitoring, cost tracking, and prompt management. This tool empowers organizations to build, deploy, and scale production-ready LLM applications with greater efficiency and control, abstracting away complexities of multi-provider integrations and ensuring operational excellence.
What It Does
Portkey AI acts as an intelligent proxy layer for LLM API calls, providing a unified interface across various AI providers while adding critical functionalities. It intercepts and processes requests, enabling features like caching, automatic retries, fallbacks, and load balancing to improve application reliability and performance. Concurrently, its observability suite captures detailed metrics on usage, costs, latency, and errors, offering deep insights into AI application behavior and facilitating optimization.
Pricing
Pricing Plans
Ideal for individuals and small projects to get started with basic LLM gateway and observability features.
- 100k requests/month
- 1 month log retention
- Basic gateway features
- Basic observability
- Community support
Designed for growing teams and production applications requiring enhanced reliability, performance, and collaboration features. Overage pricing applies.
- 1M requests/month
- 3 months log retention
- Advanced gateway features (Semantic Caching, A/B Testing, Load Balancing)
- Advanced observability
- Team collaboration
- +1 more
Tailored for large organizations with specific needs for scale, security, and dedicated resources for mission-critical AI applications.
- Unlimited requests
- Custom log retention
- Dedicated infrastructure
- Advanced security & compliance
- SLAs
- +1 more
Core Value Propositions
Enhanced LLM Application Reliability
Automated retries, fallbacks, and load balancing ensure your AI applications remain stable and responsive, even when underlying APIs face issues.
Significant Cost Reduction
Intelligent caching and detailed cost tracking help identify and implement strategies to reduce LLM API expenses, optimizing your operational budget.
Accelerated Development & Deployment
A unified API gateway and streamlined prompt management reduce development overhead, allowing teams to build and deploy AI features faster.
Deep Operational Visibility
Real-time monitoring of latency, errors, and usage provides crucial insights, enabling proactive issue resolution and continuous performance improvement.
Seamless Multi-Provider Integration
Easily switch or combine multiple LLM providers without extensive code changes, future-proofing your applications and reducing vendor lock-in.
Use Cases
Building Reliable AI Chatbots
Ensure chatbots remain responsive and available by using automated retries and fallbacks across multiple LLM providers, enhancing user experience.
Optimizing LLM API Costs
Reduce expenses by implementing semantic caching for frequently asked questions and monitoring usage to identify areas for cost-saving optimizations.
A/B Testing Prompt Engineering
Experiment with different prompt versions in a live environment to determine which performs best for specific use cases or user segments, improving output quality.
Centralized Prompt Management
Manage and version all prompts from a single interface, ensuring consistency and facilitating collaboration across development and product teams for various AI features.
Monitoring Production AI Applications
Gain real-time insights into latency, errors, and token usage for all LLM interactions, allowing for proactive issue detection and performance tuning.
Seamlessly Switching LLM Providers
Migrate or integrate new LLM providers without modifying application code, providing flexibility and reducing vendor lock-in for evolving AI strategies.
Technical Features & Integration
Unified AI Gateway
Access multiple LLM providers (OpenAI, Anthropic, Google, etc.) via a single API endpoint, streamlining integration and enabling provider flexibility without code changes.
Automatic Retries & Fallbacks
Enhance application reliability by automatically retrying failed requests and intelligently falling back to alternative models or providers when primary ones fail.
Intelligent Caching
Reduce API costs and latency with request caching, including semantic caching that intelligently identifies similar prompts to serve cached responses.
Real-time Observability
Monitor key metrics like costs, latency, tokens, and errors across all LLM interactions in real-time, providing deep insights into application performance and usage.
Prompt Management & Versioning
Organize, version, and manage prompts centrally, facilitating collaboration and ensuring consistency across different stages of development and deployment.
A/B Testing for Prompts
Experiment with different prompts and model configurations to evaluate their performance and impact on user experience directly within production environments.
Cost Tracking & Optimization
Gain detailed visibility into LLM API spend, identify cost-saving opportunities, and implement strategies to optimize expenses without sacrificing performance.
Load Balancing
Distribute LLM requests across multiple models or providers to manage traffic spikes, improve response times, and prevent single points of failure.
Target Audience
This tool is ideal for developers, MLOps engineers, and AI teams building and deploying production-grade LLM applications. Companies seeking to enhance the reliability, performance, and cost-efficiency of their AI-powered products will find Portkey AI invaluable, especially those integrating multiple LLM providers.
Frequently Asked Questions
Portkey AI offers a free plan with limited features. Paid plans are available for additional features and capabilities. Available plans include: Free, Pro, Enterprise.
Portkey AI acts as an intelligent proxy layer for LLM API calls, providing a unified interface across various AI providers while adding critical functionalities. It intercepts and processes requests, enabling features like caching, automatic retries, fallbacks, and load balancing to improve application reliability and performance. Concurrently, its observability suite captures detailed metrics on usage, costs, latency, and errors, offering deep insights into AI application behavior and facilitating optimization.
Key features of Portkey AI include: Unified AI Gateway: Access multiple LLM providers (OpenAI, Anthropic, Google, etc.) via a single API endpoint, streamlining integration and enabling provider flexibility without code changes.. Automatic Retries & Fallbacks: Enhance application reliability by automatically retrying failed requests and intelligently falling back to alternative models or providers when primary ones fail.. Intelligent Caching: Reduce API costs and latency with request caching, including semantic caching that intelligently identifies similar prompts to serve cached responses.. Real-time Observability: Monitor key metrics like costs, latency, tokens, and errors across all LLM interactions in real-time, providing deep insights into application performance and usage.. Prompt Management & Versioning: Organize, version, and manage prompts centrally, facilitating collaboration and ensuring consistency across different stages of development and deployment.. A/B Testing for Prompts: Experiment with different prompts and model configurations to evaluate their performance and impact on user experience directly within production environments.. Cost Tracking & Optimization: Gain detailed visibility into LLM API spend, identify cost-saving opportunities, and implement strategies to optimize expenses without sacrificing performance.. Load Balancing: Distribute LLM requests across multiple models or providers to manage traffic spikes, improve response times, and prevent single points of failure..
Portkey AI is best suited for This tool is ideal for developers, MLOps engineers, and AI teams building and deploying production-grade LLM applications. Companies seeking to enhance the reliability, performance, and cost-efficiency of their AI-powered products will find Portkey AI invaluable, especially those integrating multiple LLM providers..
Automated retries, fallbacks, and load balancing ensure your AI applications remain stable and responsive, even when underlying APIs face issues.
Intelligent caching and detailed cost tracking help identify and implement strategies to reduce LLM API expenses, optimizing your operational budget.
A unified API gateway and streamlined prompt management reduce development overhead, allowing teams to build and deploy AI features faster.
Real-time monitoring of latency, errors, and usage provides crucial insights, enabling proactive issue resolution and continuous performance improvement.
Easily switch or combine multiple LLM providers without extensive code changes, future-proofing your applications and reducing vendor lock-in.
Ensure chatbots remain responsive and available by using automated retries and fallbacks across multiple LLM providers, enhancing user experience.
Reduce expenses by implementing semantic caching for frequently asked questions and monitoring usage to identify areas for cost-saving optimizations.
Experiment with different prompt versions in a live environment to determine which performs best for specific use cases or user segments, improving output quality.
Manage and version all prompts from a single interface, ensuring consistency and facilitating collaboration across development and product teams for various AI features.
Gain real-time insights into latency, errors, and token usage for all LLM interactions, allowing for proactive issue detection and performance tuning.
Migrate or integrate new LLM providers without modifying application code, providing flexibility and reducing vendor lock-in for evolving AI strategies.
Get new AI tools weekly
Join readers discovering the best AI tools every week.