
Portkey
Last updated:
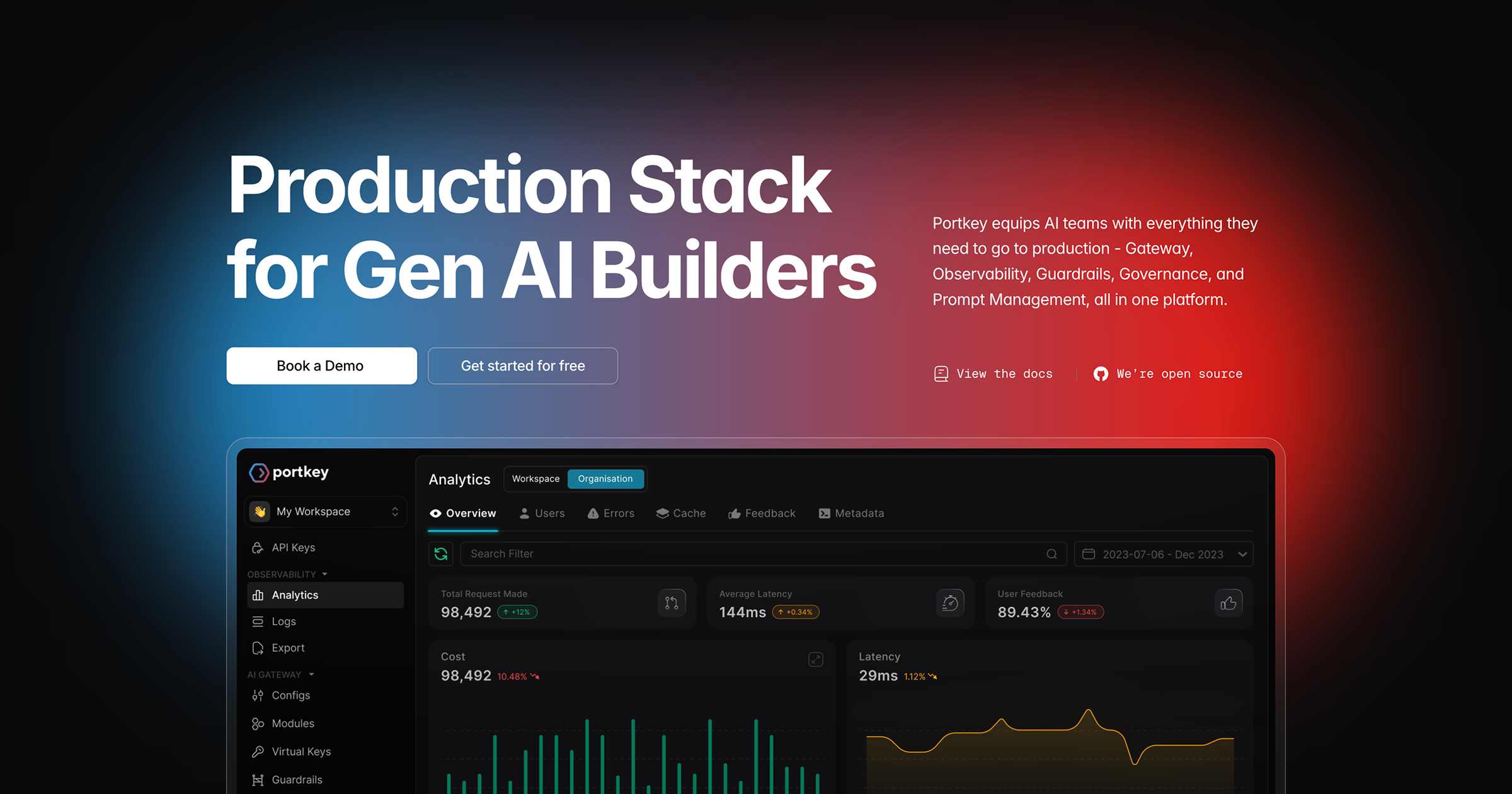
Portkey is a comprehensive full-stack LLMOps platform designed to empower developers in building, deploying, and managing robust large language model (LLM) applications. It provides a unified suite of tools encompassing observability, prompt management, an intelligent API gateway, and experimentation capabilities like A/B testing. By streamlining critical aspects of LLM development and operations, Portkey enables teams to enhance performance, reduce costs, and ensure the reliability and scalability of their AI-powered solutions. It serves as a crucial infrastructure layer for anyone serious about taking LLM prototypes to production-grade applications.
What It Does
Portkey acts as an intelligent layer between your application and various LLM providers, offering a unified API for seamless interaction. It automatically logs all LLM calls, providing deep insights into performance, costs, and errors through its observability features. The platform also enables developers to manage prompts, implement caching, fallbacks, and A/B tests directly through its gateway, optimizing LLM interactions and improving application resilience.
Pricing
Pricing Plans
Ideal for individuals and small projects to get started with LLMOps and monitor basic LLM interactions.
- Up to 500k requests/month
- 7-day data retention
- Community support
- Observability
- Gateway features
- +1 more
Designed for growing teams needing extensive data retention, higher usage limits, and dedicated support for production applications.
- Up to 2M requests/month included
- Unlimited data retention
- Priority support
- All Free features
- Advanced analytics
- +1 more
Tailored for large organizations requiring custom solutions, on-premise deployment, and enterprise-grade support and security.
- Custom request volumes
- Self-hosting options
- Dedicated support
- Advanced security features
- SLA guarantees
Core Value Propositions
Accelerate LLM Development
Streamline the entire LLM application lifecycle from development to deployment, enabling faster iteration and time-to-market for AI products.
Enhance Application Reliability
Ensure consistent performance and uptime with features like intelligent caching, automatic retries, and fallbacks across various LLM providers.
Optimize Costs and Performance
Gain granular insights into LLM usage and spending, allowing for data-driven decisions to reduce API costs and improve response times.
Improve Prompt Engineering
Version, manage, and test prompts effectively, enabling continuous improvement of LLM outputs and better control over application behavior.
Use Cases
Building Production AI Chatbots
Ensure high availability and low latency for conversational AI applications by utilizing Portkey's caching, load balancing, and fallback mechanisms.
Developing Intelligent Agents
Manage interactions with multiple LLM providers and complex prompt chains, ensuring robust and reliable operation for sophisticated AI agents.
Optimizing Content Generation
A/B test different prompt versions and models for content creation tasks to identify the most effective strategies for quality and cost efficiency.
Monitoring LLM Application Health
Gain real-time insights into LLM API calls, errors, and costs to quickly identify and resolve performance bottlenecks or unexpected spending.
Iterative Prompt Engineering
Version control and experiment with various prompts to continuously improve the quality and relevance of LLM outputs in live applications.
Technical Features & Integration
LLM API Gateway
Unify access to multiple LLM providers (OpenAI, Anthropic, Google, etc.) through a single API endpoint, simplifying integration and future-proofing your application architecture.
Real-time Observability
Monitor and analyze LLM calls with detailed logs, traces, and metrics for cost, latency, token usage, and errors, providing crucial insights into application performance.
Prompt Management
Version control, organize, and test prompts within a dedicated playground, ensuring consistent prompt quality and facilitating collaborative development.
Caching & Retries
Reduce latency and API costs by caching common LLM responses and automatically retrying failed requests, enhancing application speed and reliability.
A/B Testing & Experimentation
Run controlled experiments on different prompts, models, or configurations to optimize LLM output and measure the impact on user experience and business metrics.
Cost Optimization
Track and analyze LLM spending across various models and prompts, identifying areas for cost reduction through caching, model selection, and efficient prompt design.
Fallbacks & Load Balancing
Configure backup LLMs for failover scenarios and distribute requests across multiple models or providers, improving application resilience and scalability.
Target Audience
Portkey is primarily designed for AI engineers, machine learning teams, and software developers building and deploying LLM-powered applications. It's ideal for startups and enterprises focused on bringing reliable, scalable, and cost-efficient AI solutions to production. Teams needing robust monitoring, prompt versioning, and performance optimization will find it invaluable.
Frequently Asked Questions
Portkey offers a free plan with limited features. Paid plans are available for additional features and capabilities. Available plans include: Free, Pro, Enterprise.
Portkey acts as an intelligent layer between your application and various LLM providers, offering a unified API for seamless interaction. It automatically logs all LLM calls, providing deep insights into performance, costs, and errors through its observability features. The platform also enables developers to manage prompts, implement caching, fallbacks, and A/B tests directly through its gateway, optimizing LLM interactions and improving application resilience.
Key features of Portkey include: LLM API Gateway: Unify access to multiple LLM providers (OpenAI, Anthropic, Google, etc.) through a single API endpoint, simplifying integration and future-proofing your application architecture.. Real-time Observability: Monitor and analyze LLM calls with detailed logs, traces, and metrics for cost, latency, token usage, and errors, providing crucial insights into application performance.. Prompt Management: Version control, organize, and test prompts within a dedicated playground, ensuring consistent prompt quality and facilitating collaborative development.. Caching & Retries: Reduce latency and API costs by caching common LLM responses and automatically retrying failed requests, enhancing application speed and reliability.. A/B Testing & Experimentation: Run controlled experiments on different prompts, models, or configurations to optimize LLM output and measure the impact on user experience and business metrics.. Cost Optimization: Track and analyze LLM spending across various models and prompts, identifying areas for cost reduction through caching, model selection, and efficient prompt design.. Fallbacks & Load Balancing: Configure backup LLMs for failover scenarios and distribute requests across multiple models or providers, improving application resilience and scalability..
Portkey is best suited for Portkey is primarily designed for AI engineers, machine learning teams, and software developers building and deploying LLM-powered applications. It's ideal for startups and enterprises focused on bringing reliable, scalable, and cost-efficient AI solutions to production. Teams needing robust monitoring, prompt versioning, and performance optimization will find it invaluable..
Streamline the entire LLM application lifecycle from development to deployment, enabling faster iteration and time-to-market for AI products.
Ensure consistent performance and uptime with features like intelligent caching, automatic retries, and fallbacks across various LLM providers.
Gain granular insights into LLM usage and spending, allowing for data-driven decisions to reduce API costs and improve response times.
Version, manage, and test prompts effectively, enabling continuous improvement of LLM outputs and better control over application behavior.
Ensure high availability and low latency for conversational AI applications by utilizing Portkey's caching, load balancing, and fallback mechanisms.
Manage interactions with multiple LLM providers and complex prompt chains, ensuring robust and reliable operation for sophisticated AI agents.
A/B test different prompt versions and models for content creation tasks to identify the most effective strategies for quality and cost efficiency.
Gain real-time insights into LLM API calls, errors, and costs to quickly identify and resolve performance bottlenecks or unexpected spending.
Version control and experiment with various prompts to continuously improve the quality and relevance of LLM outputs in live applications.
Get new AI tools weekly
Join readers discovering the best AI tools every week.