
Honeyhive AI
Last updated:
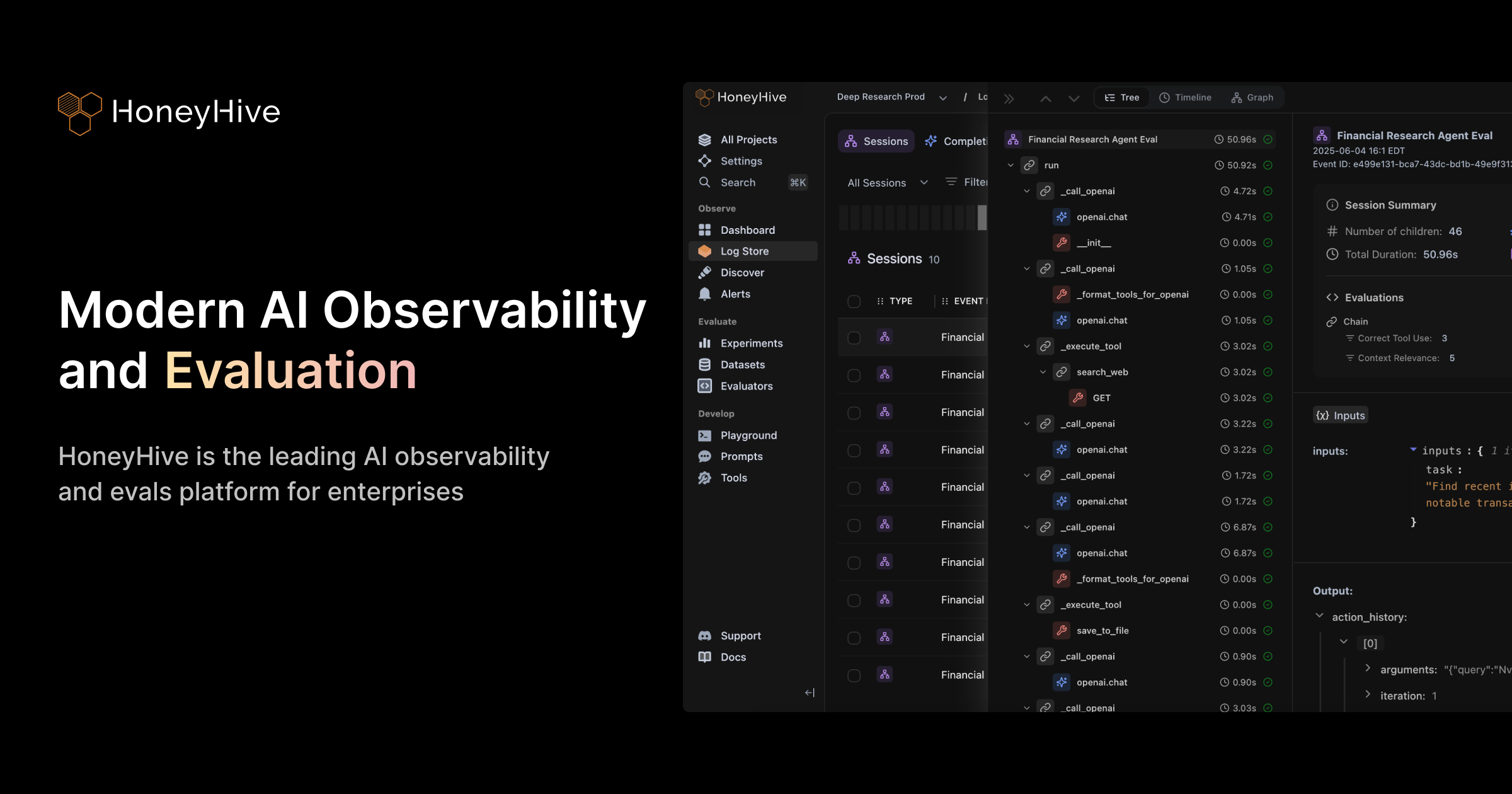
Honeyhive AI is a comprehensive observability and evaluation platform meticulously designed for developers and teams building Large Language Model (LLM) applications. It provides the necessary tools to monitor LLMs in production, rigorously evaluate their performance and quality, and facilitate efficient fine-tuning. By offering deep insights into application behavior, costs, and user interactions, Honeyhive AI empowers teams to reduce development risks, accelerate iteration cycles, and ensure their LLM-powered products meet high standards of reliability and efficiency in real-world scenarios.
What It Does
The platform acts as a central hub for managing the entire LLM application lifecycle post-development. It captures and visualizes data from prompts, responses, and user feedback, allowing for automated and human-in-the-loop evaluation of model outputs. Furthermore, Honeyhive AI supports data curation for fine-tuning, enabling continuous improvement of LLM performance and cost-efficiency directly within the platform.
Pricing
Pricing Plans
A free tier to get started with basic observability and evaluation features.
Tailored plans for larger teams and enterprises requiring advanced features, dedicated support, and higher usage limits.
Core Value Propositions
Enhanced LLM Reliability
Gain deep visibility into model behavior and performance, significantly reducing unexpected issues in production.
Accelerated Development Cycles
Streamline evaluation and fine-tuning workflows, enabling faster iteration and deployment of improved LLM applications.
Optimized Costs and Performance
Monitor and analyze cost and latency metrics to identify areas for optimization, ensuring efficient resource utilization.
Data-driven Decision Making
Leverage comprehensive data from production to make informed decisions about model improvements and prompt strategies.
Use Cases
Monitoring AI Chatbot Performance
Track user interactions, response quality, and latency for AI-powered chatbots to identify conversational breakdowns and areas for improvement.
Evaluating Search & Recommendation LLMs
A/B test different LLM models or prompt strategies for search relevance and recommendation accuracy, ensuring optimal user experience.
Fine-tuning Content Generation Models
Collect and curate real-world data from content outputs and user feedback to fine-tune LLMs for more accurate and brand-aligned content generation.
Detecting LLM Hallucinations
Implement guardrails and automated evaluations to identify and mitigate instances of LLM hallucinations or undesirable outputs in critical applications.
Optimizing LLM API Costs
Monitor token usage and API call costs across different models and prompts to make data-driven decisions on cost-efficient LLM deployments.
Benchmarking LLM Models
Rigorously compare the performance of various proprietary and open-source LLMs on custom datasets to select the best model for a specific task.
Technical Features & Integration
Full-stack LLM Observability
Monitor prompts, responses, latency, costs, and user feedback across your LLM applications in production, providing a complete picture of performance and behavior.
Automated & Human Evaluation
Conduct rigorous testing of models and prompts using automated metrics and integrate human reviewers to ensure output quality and relevance.
Dataset Management & Curation
Collect, label, and manage high-quality datasets directly from production data, streamlining the process of preparing data for fine-tuning.
LLM Fine-tuning Capabilities
Leverage curated datasets to fine-tune various LLMs (OpenAI, Anthropic, open-source) directly within the platform, optimizing models for specific use cases.
Prompt Engineering & Versioning
Experiment with different prompts, manage their versions, and track performance changes over time to continuously improve model interactions.
A/B Testing for LLMs
Compare the performance of different models, prompts, or configurations in a controlled environment to identify the most effective solutions.
Cost & Latency Monitoring
Track the financial implications and response times of your LLM applications, helping to identify inefficiencies and optimize resource usage.
Integrations with AI Stacks
Seamlessly integrates with popular LLM frameworks and providers like LangChain, LlamaIndex, OpenAI, and Anthropic, fitting into existing workflows.
Target Audience
This tool is ideal for ML engineers, data scientists, product managers, and software developers who are actively building, deploying, and scaling LLM-powered applications. Teams focused on ensuring the reliability, performance, and cost-efficiency of their AI products in production environments will find Honeyhive AI invaluable for their development lifecycle.
Frequently Asked Questions
Honeyhive AI offers a free plan with limited features. Paid plans are available for additional features and capabilities. Available plans include: Starter, Custom/Enterprise.
The platform acts as a central hub for managing the entire LLM application lifecycle post-development. It captures and visualizes data from prompts, responses, and user feedback, allowing for automated and human-in-the-loop evaluation of model outputs. Furthermore, Honeyhive AI supports data curation for fine-tuning, enabling continuous improvement of LLM performance and cost-efficiency directly within the platform.
Key features of Honeyhive AI include: Full-stack LLM Observability: Monitor prompts, responses, latency, costs, and user feedback across your LLM applications in production, providing a complete picture of performance and behavior.. Automated & Human Evaluation: Conduct rigorous testing of models and prompts using automated metrics and integrate human reviewers to ensure output quality and relevance.. Dataset Management & Curation: Collect, label, and manage high-quality datasets directly from production data, streamlining the process of preparing data for fine-tuning.. LLM Fine-tuning Capabilities: Leverage curated datasets to fine-tune various LLMs (OpenAI, Anthropic, open-source) directly within the platform, optimizing models for specific use cases.. Prompt Engineering & Versioning: Experiment with different prompts, manage their versions, and track performance changes over time to continuously improve model interactions.. A/B Testing for LLMs: Compare the performance of different models, prompts, or configurations in a controlled environment to identify the most effective solutions.. Cost & Latency Monitoring: Track the financial implications and response times of your LLM applications, helping to identify inefficiencies and optimize resource usage.. Integrations with AI Stacks: Seamlessly integrates with popular LLM frameworks and providers like LangChain, LlamaIndex, OpenAI, and Anthropic, fitting into existing workflows..
Honeyhive AI is best suited for This tool is ideal for ML engineers, data scientists, product managers, and software developers who are actively building, deploying, and scaling LLM-powered applications. Teams focused on ensuring the reliability, performance, and cost-efficiency of their AI products in production environments will find Honeyhive AI invaluable for their development lifecycle..
Gain deep visibility into model behavior and performance, significantly reducing unexpected issues in production.
Streamline evaluation and fine-tuning workflows, enabling faster iteration and deployment of improved LLM applications.
Monitor and analyze cost and latency metrics to identify areas for optimization, ensuring efficient resource utilization.
Leverage comprehensive data from production to make informed decisions about model improvements and prompt strategies.
Track user interactions, response quality, and latency for AI-powered chatbots to identify conversational breakdowns and areas for improvement.
A/B test different LLM models or prompt strategies for search relevance and recommendation accuracy, ensuring optimal user experience.
Collect and curate real-world data from content outputs and user feedback to fine-tune LLMs for more accurate and brand-aligned content generation.
Implement guardrails and automated evaluations to identify and mitigate instances of LLM hallucinations or undesirable outputs in critical applications.
Monitor token usage and API call costs across different models and prompts to make data-driven decisions on cost-efficient LLM deployments.
Rigorously compare the performance of various proprietary and open-source LLMs on custom datasets to select the best model for a specific task.
Get new AI tools weekly
Join readers discovering the best AI tools every week.